
 基因测序仪业务
基因测序仪业务









 技术解读
技术解读 热门应用
热门应用 组学研究(科研方向)
组学研究(科研方向) 组学研究(临床方向)
组学研究(临床方向) 文档下载
文档下载 已发表文章
已发表文章 用户成功案例
用户成功案例 在线数据集
在线数据集 多功能中心
多功能中心 客户中心
客户中心 在线支持
在线支持







近日,华大智造宣布其CoolMPS测序产品将从今年4月份开始正式进入美国市场,并在刚结束不久的基因测序技术全球盛会AGBT上联合多位海外科学家共同分享了基于DNBSEQ测序平台上的CoolMPS™测序数据,从理论到实践综合体现了华大智造DNBSEQ™的技术优势。

华大智造首席科学家Rade Drmanac博士在AGBT上发表演讲
而在此之前,该技术已引发业界广泛关注与讨论,且有诸多境外平台及媒体对其进行探索与分析。例如,2月19日bioRxiv发表的预印文章[1]对华大智造CoolMPS™化学进行了全面概述。紧接着,Omics! Omics!也刊发了相关文章。本文,我们将援引海外专家Keith Robison博士发表的评论文章,以专业人士第一人称角度对该技术进行深入解读。

bioRxiv预印文章对华大智造CoolMPSTM化学进行了全面概述
Illumina的合成测序平台和QIAGEN已淘汰的平台,均使用了荧光标记的可逆终止子。在理想情况下,荧光标记可成为终止子的组成部分,然而由于空间位阻原因,往往难以实现。荧光标记的可逆终止子,在去除荧光和可逆终止子之后,会在核苷酸上留下“疤痕”。目前,还没有哪种化学能在去除荧光之后留下天然核苷酸,其“疤痕”会影响后续聚合。这种可逆终止子的化学合成很复杂,而且合成步骤越多,产量越低。华大智造CoolMPS™使用的是没有荧光标记的可逆终止子,它采用特定的抗体来检测可逆终止子。我认为华大智造在这方面具有一定的创新性,他们使用了天然碱基,并且最后成功筛选出了所需抗体,预印本详细描述了这一筛选过程。

华大智造CoolMPS高通量测序试剂套装
抗体标记的优势
更亮
与标记核苷酸相比,标记抗体的显著优势是:一个抗体可以标记多个荧光分子。预印本描述了标记抗体的亮度比标记终止子的高3倍。
更多优化空间
通过优化不同条件来提高抗体结合化学,比如通过蛋白工程方法来提高抗体的结合能力,或者在一个抗体上标记更多荧光分子;还可以进一步优化各种反应时间和缓冲液。
克服“疤痕”带来的信号抑制
预印本介绍了标记的可逆终止子产生的疤痕可能会对信号产生淬灭效应:如果上一个碱基是T, G信号就会被抑制,而CoolMPS™未见任何信号抑制。
数据表现
在测序测试中,华大智造使用DNA纳米球(将滚环复制产生的DNA纳米球作为测序模板)进行了200个循环测序,这些DNA纳米球由平均插入长度为300bp的大肠杆菌文库制成。预印本中的曲线图显示了信号随循环数的增加而衰减,以及位置不一致性,即信号中与参考碱基相比较的噪声量。他们将大部分位置不一致性的原因归结于异相信号与染料串扰相混淆以及信号丢失,特别是在拷贝数少的DNA纳米球中。最终,经过200个循环测试后,总信号的30%是-1或+1的异相信号。奇怪的是,图例中注释显示,在185循环之后,不一致性急剧增长,可能是由于插入片段短或者测到接头序列造成的。对于该测试,应使用与插入片段大小控制更佳的文库,或特定插入片段的文库,这样才能准确测量这一重要参数。
在PCR-free的大肠杆菌文库中使用了100bp读长来进行总体准确性测试。由于DNA纳米球不涉及PCR,而Illumina的模板准备会涉及,他们强调PCR可能存在错误。从流体学、光学和DNA纳米球的尺寸方面挑选出阵列的最佳区域,他们发现总体不一致性为0.029%,phred质量评分为20分或更高的碱基错误率为1/20,000,即phred 43。
信号更强的好处是测序的数据质量更高,即使DNA纳米球的拷贝数低,也能得到明亮的信号。为了验证这一点,他们使用了含400bp平均插入片段的文库,该文库在10分钟滚环复制反应中大约生成了50个拷贝,错误率为0.055%。
优化测序策略:双端及长读长
华大智造设计了双端测序策略。标准的DNA纳米球是一条链的许多拷贝,它们由滚换扩增机制实现。对于双末端测序,MDA反应使用引物产生互补链,聚合酶将产生许多个这样的链,以超支化几何形式挂在原来的DNA纳米球上。
在2x100测试中,二链信号明显减弱,准确性也有所下降,但仍可以产生比对率高于99%的可用数据。如果华大智造将测得的数据上传到第三方进行分析,就非常有价值了。缺少这样的数据集是该预印本的重大遗憾。
华大智造尝试的另一个方向是对合成测序系统进行超长读取:SE400 400个碱基的单端测序。如今在PacBio和牛津纳米孔时代,虽然SE400不算长,但比Illumina或Ion Torrent提供的都长——尽管454确实有1kb的试剂盒(据我了解,只有一小部分有那么长)。91%的碱基是Q30。同样,如果能下载这些数据集是非常有用的,我不喜欢任何现成的统计数据。有趣的是,在300个碱基之后,预计只有30个模板拷贝给出正确信号,如果给定更多初始模板拷贝的话情况会更好,当增加每个DNB的模板拷贝数,更好的标记,解决异相位合成及信号丢失问题,则可以达到500甚至700个碱基。

华大智造MGISEQ-2000测序平台(DNBSEQ-G400)
使用2-color成像进行4-color测序
在很长一段时间内,Illumina大多数仪器都使用的是2-color成像,其成像时间更短,但使用的是没有任何标记的G碱基。因此,NextSeq和NovaSeq测序仪的数据有时需要长时间进行G碱基运行,这意味着长时间无信号运行。
据我了解,华大智造在读取信号时可以简单地使用两轮标记法,分组读取两个碱基。除了硬件简单之外,其另一个优势是可以挑选由现有成像仪器实现最佳分离的两种染料。此外,两种染料可以很好地分离,省去了昂贵的带通过滤器,这也意味着来自荧光的信号不会被过滤器过滤掉。华大智造将这种方法称为“两色成像上的四色CoolMPS”或4cs2ci,其标准为4cs4ci。对于2-color模式,首先检测嘌呤A和G,洗脱后检测嘧啶C和T。
将4cs4ci和4cs2ci生成的数据进行比较,我们发现使用2-color模式过滤后的reads略多。总体测序的出错率平均降低了5.1倍(读T时,出错率降低1.7倍;读G时,出错率降低18.6倍)。从12个可能的miscall中挑出4个来看,从G到C的错误减少了52.2倍,希望已包含完整的12种miscall模式。
总结
在该pre-print最后,有一个表格总结了CoolMPS和DNBSEQ平台上CoolMPS相对于其他方法的所有优势(如下表)。未标记的核苷酸具有较低的合成成本、较高的合成率和较少的疤痕干扰。抗体检测可以实现更高强度的标记,更少的DNA光损伤,因为标记离得更远,以及上面提到的两种颜色方法的优点。
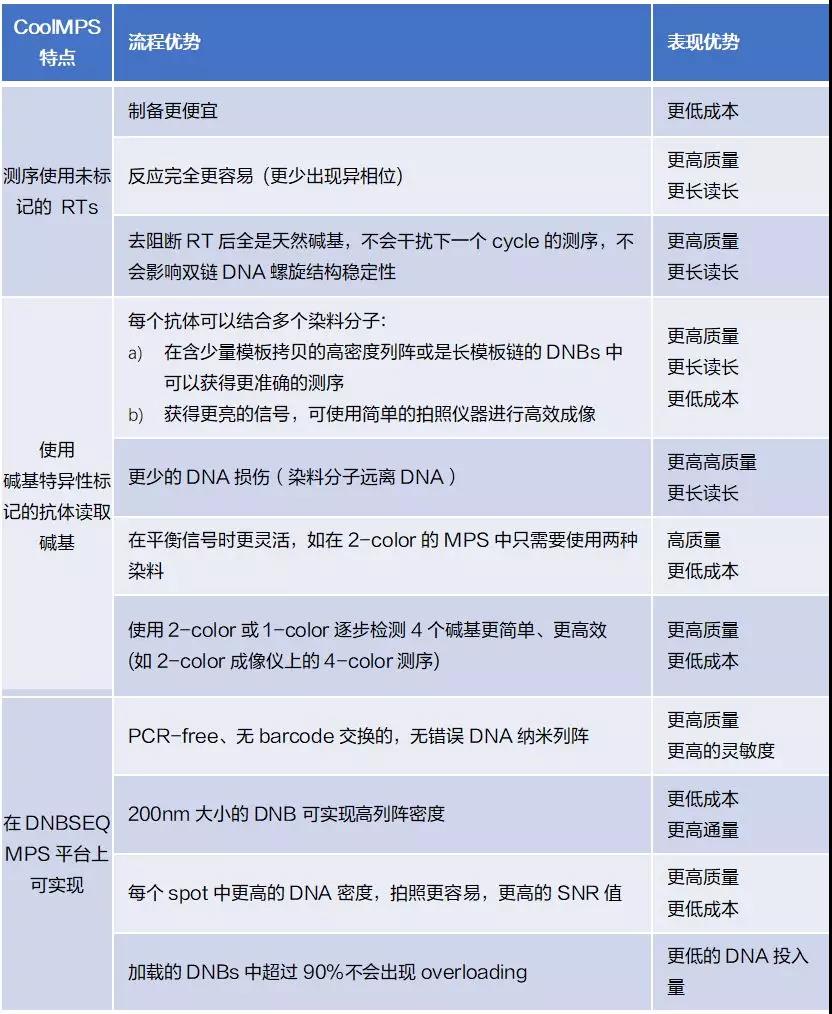
其次是DNBSEQ:PCR-free,且没有barcode交换, 高密度的200nm DNB,每个spot的高密度带来成像优势,以及该pre-print中并未探索的”超过90%的DNB在加载时不会出现overloading”,因此可以实现DNA低投入。
在该部分测试中,华大智造指出,低拷贝DNB的强信号表明可以产生更小的DNB,每张载片能得到更紧密堆积和更多亮点。此外,还可以用多种染料来标记抗体,且需要具有这两种染料正确signature的basecall。
我看到华大智造还展示了2个光通道上的4种颜色明显延伸到1个光通道上的4种颜色。据推测,这将用于其正在开发的DNBSEQ E系列便携式测序系统。
我希望后续能与华大智造的技术专家们进行更多交流。
参考链接:
[1]doi:https://doi.org/10.1101/2019.12.20.885517
[2]http://omicsomics.blogspot.com/2020/02/coolmps-revealed.html











